Описание
Тест с ответами “Введение в анализ больших данных” Синергия>100 баллов Итоговый тест Экзамен.



₽250
Тест с ответами “Введение в анализ больших данных” Синергия>100 баллов Итоговый тест Экзамен.

Концепции современного естествознания ответы на тесты Синергия МФПУ / зачет 87 баллов

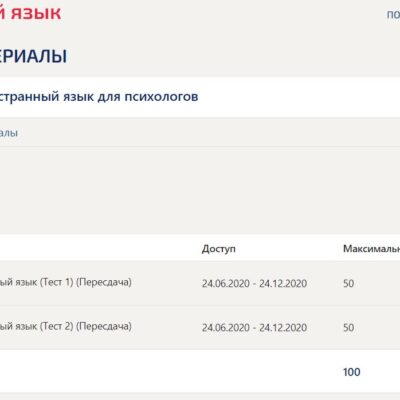
Ответы Английский язык синергия , тест 30 вопросов – оценка Отлично

Дошкольная педагогика Синергия ответы(тесты 80/100 баллов )